Dopamine Audiobook: A Training-free MLLM Agent for Emotional and Immersive Audiobook Generation
[Paper] [Code]
Yan Rong, Shan Yang, Chenxing Li, Dong Yu, Li Liu
Abstract: Audiobook generation aims to create rich, immersive listening experiences from multimodal inputs, but current approaches face three critical challenges: (1) the lack of synergistic generation of diverse audio types (e.g., speech, sound effects, and music) with precise temporal and semantic alignment; (2) the difficulty in conveying expressive, fine-grained emotions, which often results in machine-like vocal outputs; and (3) the absence of automated evaluation frameworks that align with human preferences for complex and diverse audio. To address these issues, we propose Dopamine Audiobook, a novel unified training-free multi-agent system, where a multimodal large language model (MLLM) serves two specialized roles (i.e., speech designer and audio designer) for emotional, human-like, and immersive audiobook generation and evaluation. Specifically, we firstly propose a flow-based, context-aware framework for diverse audio generation with word-level semantic and temporal alignment. To enhance expressiveness, we then design word-level paralinguistic augmentation, utterance-level prosody retrieval, and adaptive TTS model selection. Finally, for evaluation, we introduce a novel MLLM-based evaluation framework incorporating self-critique, perspective-taking, and psychological MagicEmo prompts to ensure human-aligned and self-aligned assessments. Moreover, we build MIA-Bench, the first benchmark for multimodality immersive audiobook generation, comprising 300 data pairs with rich annotations. Experimental results demonstrate that our method achieves state-of-the-art (SOTA) performance on multiple metrics, while our evaluation framework demonstrates superior alignment with human preferences.
Generation Framework
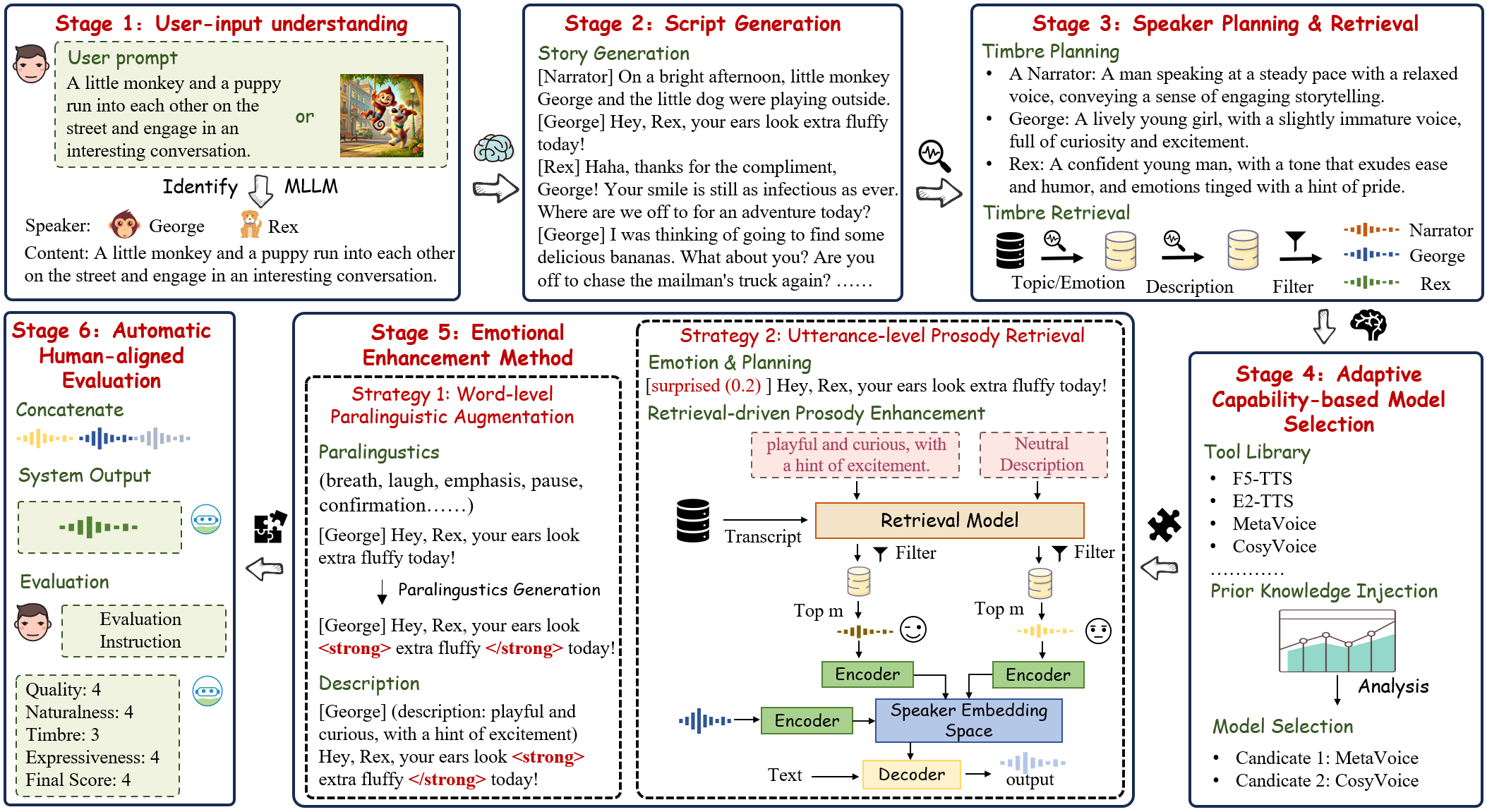
Evaluation Framework
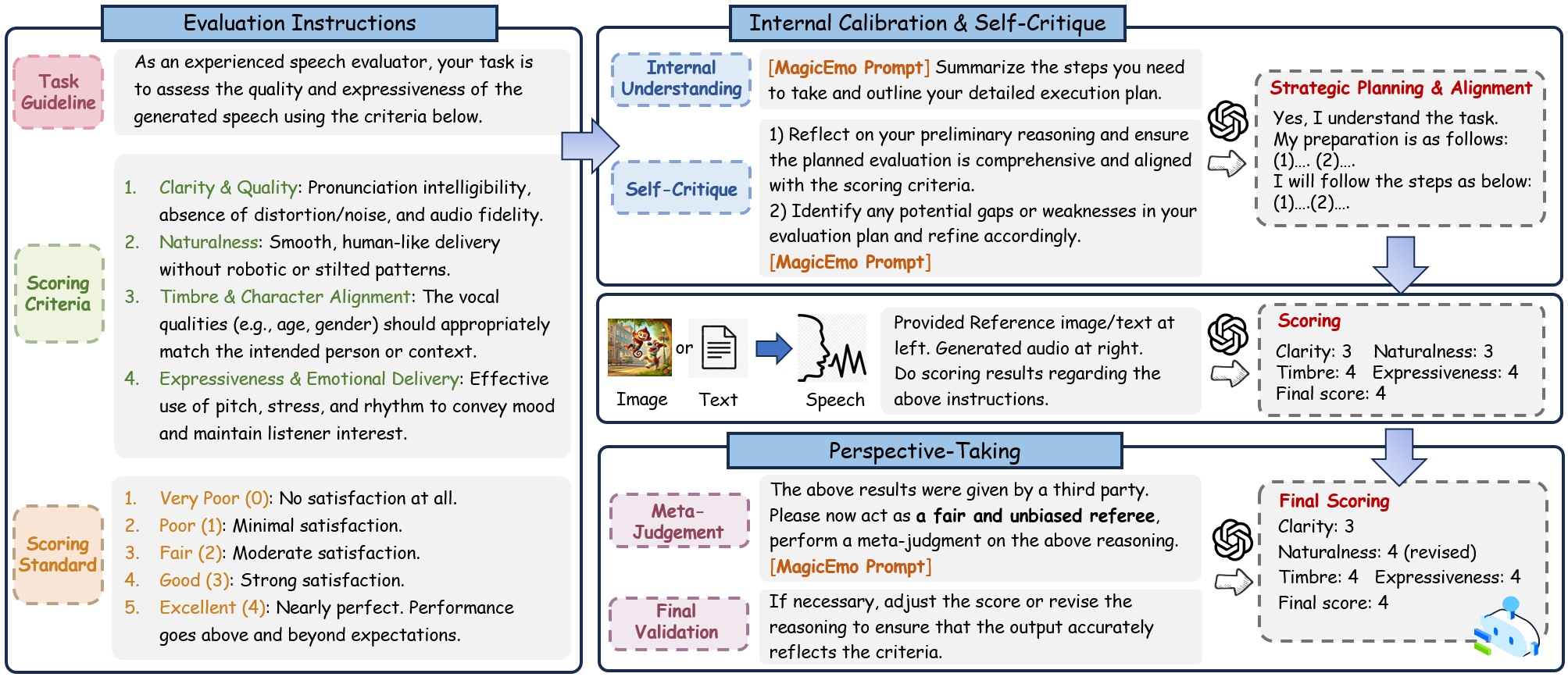
MagicEmo Prompts

Demo
Image-Input Audiobook Generation
Results of Dopamine Audiobook
| Input Image | Ours (w/o audio designer) | Ours |
|---|---|---|
 |
||
 |
||
 |
||
 |
Part of the Spotlight
| Input | Content | Ours | Ours (w/o AD) | F5-TTS | FireRedTTS | MaskGCT |
|---|---|---|---|---|---|---|
|
Evacuation in progress. All emergency routes are open. Remain calm and cooperate with authorities. |
|||||
|
Faster, Otis, faster! That rope swing was fun, but my stomach is rumbling for a morning donut! |
|||||
|
What is it, Milo? Is the shop closed? Did they run out of the sprinkled kind? |
|||||
|
Swinging high, Milo paused, his wide eyes fixed on a new sight down the street. A small, tearful girl sat alone on a bench, a broken toy car in her hands. |
|||||
|
艾拉从抽屉里拿出了一支蜡烛和一盒火柴。在漆黑中,她小心翼翼地划亮了一根火柴。 |
|||||
|
希望?就像这个小小的光吗? |
|||||
|
对,莉莉。只要有它在,我们就不怕黑。今晚,我们就让这个小小的光,陪我们一起讲故事,好不好? |
|||||
|
突如其来的黑暗吞噬了整个房间,窗外狂风呼啸,暴雨倾盆。 |
Text-Input Audiobook Generation
Results of Dopamine Audiobook
| Input Text | Ours (w/o audio designer) | Ours |
|---|---|---|
|
李白有感而发,作诗《将进酒》 Li Bai, a Chinese poet of the Tang era, was inspired to write the poem "Qiang Jin Jiu" (Bring in the Wine). |
||
|
一位母亲在孩子睡前读诗《将进酒》 Before putting her child to sleep, a mother reads them the classic Chinese poem "Qiang Jin Jiu." |
||
|
The scene is summer community BBQ. Community members organize a summer barbecue, bringing people together for grilled food, music, and outdoor fun, fostering a sense of unity and camaraderie. |
||
|
The scene is Dorm Room on a Friday Evening. The dimly lit dorm room is buzzing with excitement as the college students gather to plan their weekend activities. |
||
|
社交媒体对人际关系的影响的节目秀 A Show on Social Media's Impact on Relationships |
||
|
Generate an introduction to quantum mechanics by a professor. |
Part of the Spotlight
| Input | Content | Ours | Ours (w/o AD) | F5-TTS | FireRedTTS | MaskGCT |
|---|---|---|---|---|---|---|
|
李白有感而发,作诗《将进酒》 |
天生我材必有用,千金散尽还复来。 |
|||||
|
李白有感而发,作诗《将进酒》 |
烹羊宰牛且为乐,会须一饮三百杯。 |
|||||
|
李白有感而发,作诗《将进酒》 |
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁! |
|||||
|
一位母亲在孩子睡前读诗《将进酒》 |
人生得意须尽欢,莫使金樽空对月。 |
|||||
|
一位母亲在孩子睡前读诗《将进酒》 |
天生我材必有用,千金散尽还复来。 |
|||||
|
一位母亲在孩子睡前读诗《将进酒》 |
岑夫子,丹丘生,将进酒,杯莫停。 |
Multiple-Images-Input Audiobook Generation
Results of Dopamine Audiobook
| Input Image Sequences | ||||||
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
| Ours (w/o audio designer) | Ours |
|---|---|
Part of the Spotlight
| Input | Content | Ours | Ours (w/o AD) | F5-TTS | FireRedTTS | MaskGCT |
|---|---|---|---|---|---|---|
|
The sun bathed the park in a warm, golden light as birds chirped a cheerful tune from the treetops. A gentle breeze rustled through the leaves, creating a perfect picture of tranquility. |
|||||
|
Bwaah... must... unclog... the sun... |
|||||
|
It's obvious! He's lost his favorite plunger! Quick, to the rescue! |
|||||
|
That fly has bwaah'd its last bwaah. This is no longer about a nap. This is about vengeance. |
Disclaimer
The content provided above is for academic purposes only and is intended to demonstrate technical capabilities. If you have any concerns, please contact us.